The models we studied in Chapter 5 treat the variable of interest as dependent on its own past, and possibly on a set of exogenous variables. While this approach is useful, often, economic and financial variables may interact simultaneously rather than in isolation. For example, GDP and consumption influence each other, as do interest rates and inflation, stock returns and exchange rates, industrial production and trade flows, or sales and prices. These relationships are inherently dynamic, bidirectional, and endogenous, meaning that variables mutually influence one another. As a result, relying on a single equation model unrealistically forces the analyst to designate one variable as dependent and treat the others as exogenous. A vector Autoregression (VAR) treats all variables as endogenous. Instead of modeling one equation, we can model a system of equations where each variable depends on its own lags and the lags of all other variables. Formally:
A Vector AutoRegression (VAR) is a set of k time series regressions, in which the regressors are lagged values of all k series. With \(p\) number of lags in each of the equations is the system of equations is called a \(VAR(p)\). For \(k=2\):
In a VAR with \(k\) variables and \(p\) lags, each equation includes \(k \times p\) regressors. You estimate \(k\) separate regressions, so the system becomes a collection of standard linear regressions with identical regressors.
For instance, a VAR(1) with two variables (\(k=2\)) can be expressed as:
Stationarity. Transform the data if needed so that the \(k\) series are stationary. It will be discussed further when studying cointegration.
White noise errors
No perfect multicollinearity
Contemporaneous correlation is allowed. Errors across equations can be correlated.
Variables in the system should be plausibly related, so they can meaningfully help forecast one another. Including unrelated variables adds estimation noise without contributing predictive information, ultimately reducing forecast accuracy.
The choice of lag lengths is also fundamental, we’d like to specify models with the ability to capture the dynamic relationships among variables while maintaining parsimony. As studied earlier, information criteria is useful for this purpose, by extending the single-equation information criterion, AIC or BIC, to a system of equations, the optimal lag length is the one that minimizes the criterion. The selection, however, should be complemented with residual diagnostics (e.g., Ljung-Box test) and interpretability, asking ourselves if the lag length make sense given the frequency of the data.
The Stability Condition
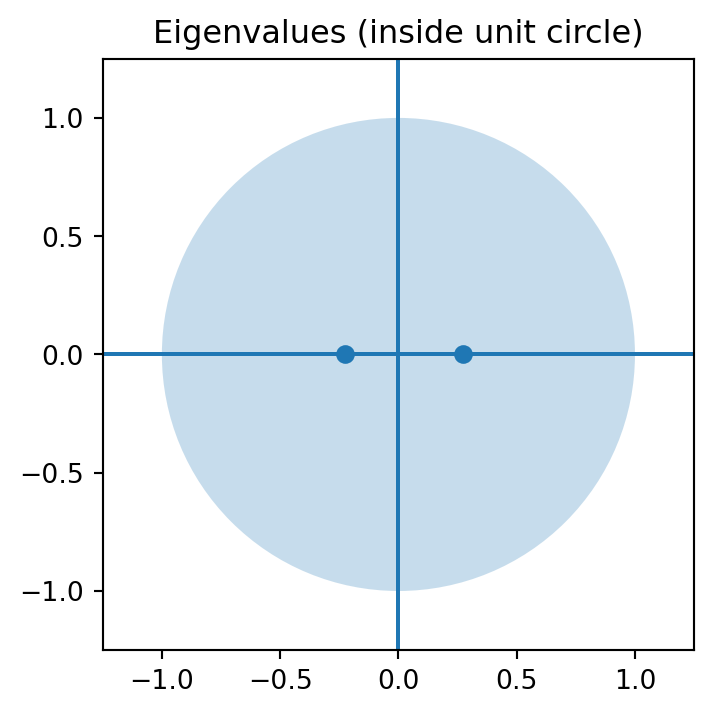
The stability condition requires all the eigenvalues of the coefficient matrix to lie inside the unit circle. The coefficient matrix in a VAR indicates how variables affect each other over time. The eigenvalues of this matrix then capture the persistence of the system:
Eigenvalues close to 1 \(\rightarrow\) highly persistent dynamics
Eigenvalues greater than 1 \(\rightarrow\) explosive behavior
Eigenvalues less than 1 \(\rightarrow\) stable, mean-reverting system
In other words, each eigenvalue must have modulus less than 1. To better understand the concept, we may think of eigenvalues as measuring how strongly shocks propagate through the system.
The key object is \(\phi^h\). If \(|\phi|<1\), then \(\phi^h \rightarrow 0\) as \(h \rightarrow \infty\), shocks die out. If \(|\phi| \ge 1\), then shocks persist or explode. This is why stationarity in the AR(1) process requires \(∣\phi∣<1\).
They key now is \(A^h\), does \(A^h \rightarrow 0\) as \(h \rightarrow \infty\)?. The matrix \(A\) in a VAR system summarizes two key features of the dynamics, (1) the directions in which the system evolves, captured by the eigenvectors, and (2) the persistence of those dynamics, captured by the eigenvalues. If all eigenvalues have modulus less than 1, then \(A \rightarrow 0\), but if any eigenvalue has modulus \(\ge 1\), \(A^h\) does not decay.
Each eigenvalue tells us how shocks evolve along its corresponding direction. If the modulus of all eigenvalues is less than one, shocks die out over time and the system is stable (stationary).
While stability means that all eigenvalues, \(\lambda_i\) of the companion matrix must satisfy be \(<1\), sometimes statistical software reports the roots, not the eigenvalues directly. These roots are the inverse of the eigenvalues: \(z_i = \frac{1}{\lambda_i}\), so the condition \(\lambda<1\) is equivalent to, roots outside the unit circle, \(z_i >1\).
In short, stability is the multivariate extension of stationarity, it ensures that the system behaves well over time and that the statistical properties needed for inference and forecasting are valid, ensuring that:
Shocks to the system do not explode over time
The effect of shocks gradually dies out
The series fluctuate around a constant mean and variance
NoteExample
Show code
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport statsmodels.api as smimport plotly.graph_objects as goimport yfinance as yffrom statsmodels.tsa.api import VARfrom datetime import datetimefrom pandas_datareader import data as pdrfrom statsmodels.tsa.stattools import adfuller, kpssfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.stats.diagnostic import acorr_ljungbox
/var/folders/wl/12fdw3c55777609gp0_kvdrh0000gn/T/ipykernel_69811/2165326570.py:2: InterpolationWarning:
The test statistic is outside of the range of p-values available in the
look-up table. The actual p-value is greater than the p-value returned.
/var/folders/wl/12fdw3c55777609gp0_kvdrh0000gn/T/ipykernel_69811/277256259.py:2: InterpolationWarning:
The test statistic is outside of the range of p-values available in the
look-up table. The actual p-value is greater than the p-value returned.
Estimation
var_data = ts[['gGDP', 'cUnem']]model = VAR(var_data) # Prepares the structure of a VAR modellag_selection = model.select_order(maxlags=8)print(lag_selection.summary())
FPE criteron measures how well the model that is expected to produce out-of-sample forecast error. The lowest value signals the smallest error. HQIC balances fit and parsimony, sitting between AIC and BIC in how strongly it penalizes model complexity.
The model with lag = 0 represents a model with no dynamics. It is included by default to verify that adding lags actually improves the model. Most criteria here select one lag.
p = lag_selection.selected_orders['aic'] # or 'bic', etc.results = model.fit(p)print(results.summary())
At a 95% confidence level, the null hypothesis of no serial correlation can’t be rejected.
Note that, in principle, the Ljung-Box test should adjust for all dynamic parameters that capture serial dependence in the residuals. In a VAR, this could be captured by the number of lagged regressors in each equation. In practice, some implementations simplify this adjustment, but for consistency with SARIMA models, we counted the number of coefficients for the lagged variables.
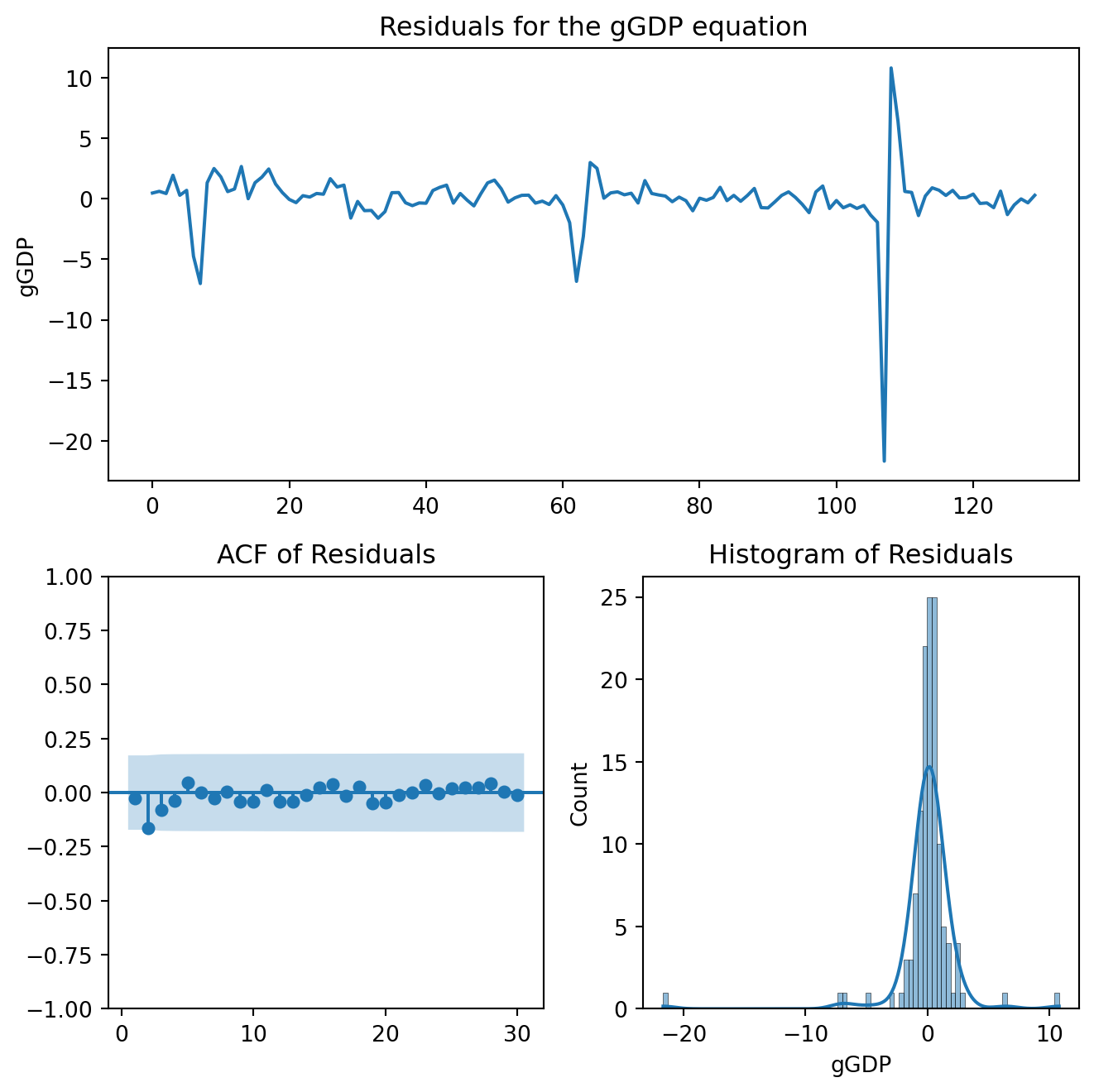
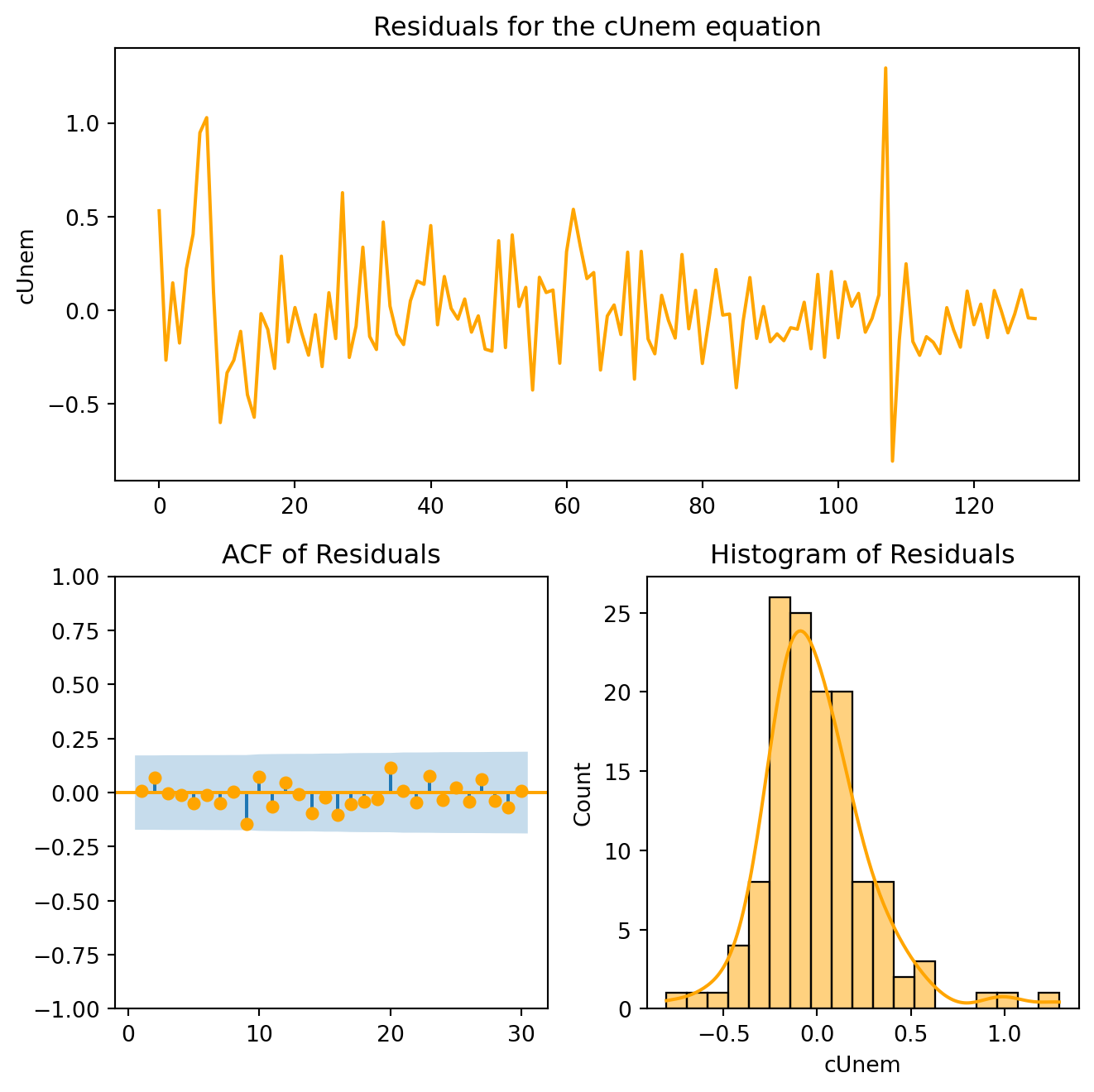
The constant (0.565) indicates an average quarterly growth around 0.6%. The coefficient on lagged GDP (-0.19, p = 0.066), implies a negative relationship, growth spikes are often followed by a decrease, a reversion to the mean. Changes in unemployment do not predict GDP growth as the coefficient is not statistically different from zero.
The constant is not statistically different from zero, i.e., we cannot reject the hypothesis that the mean change in unemployment is zero. Over time, unemployment does not trend upward or downward systematically. The coefficient on lagged GDP (-0.025), suggest that higher GDP growth reduces unemployment next period. This is an important result consistent Okun’s Law. What does the coefficient on lagged unemployment indicate?
Once a VAR has been estimated, passed the residual diagnostics, and satisfied the stability condition, we can use it either for predictive purposes or to examine relationships among the variables (or both).
6.1.1 Forecasting
The VAR provides a law of motion for the system that can be used to generate joint forecasts of all variables in which each variable is forecast using its own past and the past of all other variables.
Once the parameters have been estimated, forecasting is obtained by replacing future unknown values with their model-implied expectations conditional on the information available at the forecast origin. Suppose the last observed period is \(T\). The one-period forecast of the system is
\[
\hat{Y}_{T+1|T} = \hat{c} + \hat{A_1}Y_{T} + \hat{A_2}Y_{T-1} + \cdots + + \hat{A_p}Y_{T-p+1}
\] the forecast uses only the deterministic part implied by the estimated model because the expected value of the future innovation is zero.
The multi-period forecast follows the same logic, but now a recursion appears. The two-period forecast is
since \(Y_{T+1}\) is not observed at \(T\), it was replaced by the forecast obtained in the previous step. This recursive structure continues for longer horizons.
Important, stability was required in order to ensure that the forecast path is well behaved. In a stable VAR, the effect of shocks will diminish over time, by contrast, forecasts may explode or behave erratically in an unstable VAR, which is why such a model is not suitable for forecasting or for substantive interpretation.
periods =4forecast = results.forecast(var_data.values[-p:], steps= periods)
VAR models allow us to describe how economic systems respond to shocks. This is the purpose of impulse response analysis. In its moving average representation, the VAR model can be written as:
\(\epsilon_t\): shocks (innovations, news) \(\Phi_h\): describes how shocks propagate over time
Thus, the current value of the system can be interpreted as the accumulation of past shocks and their dynamic effects.
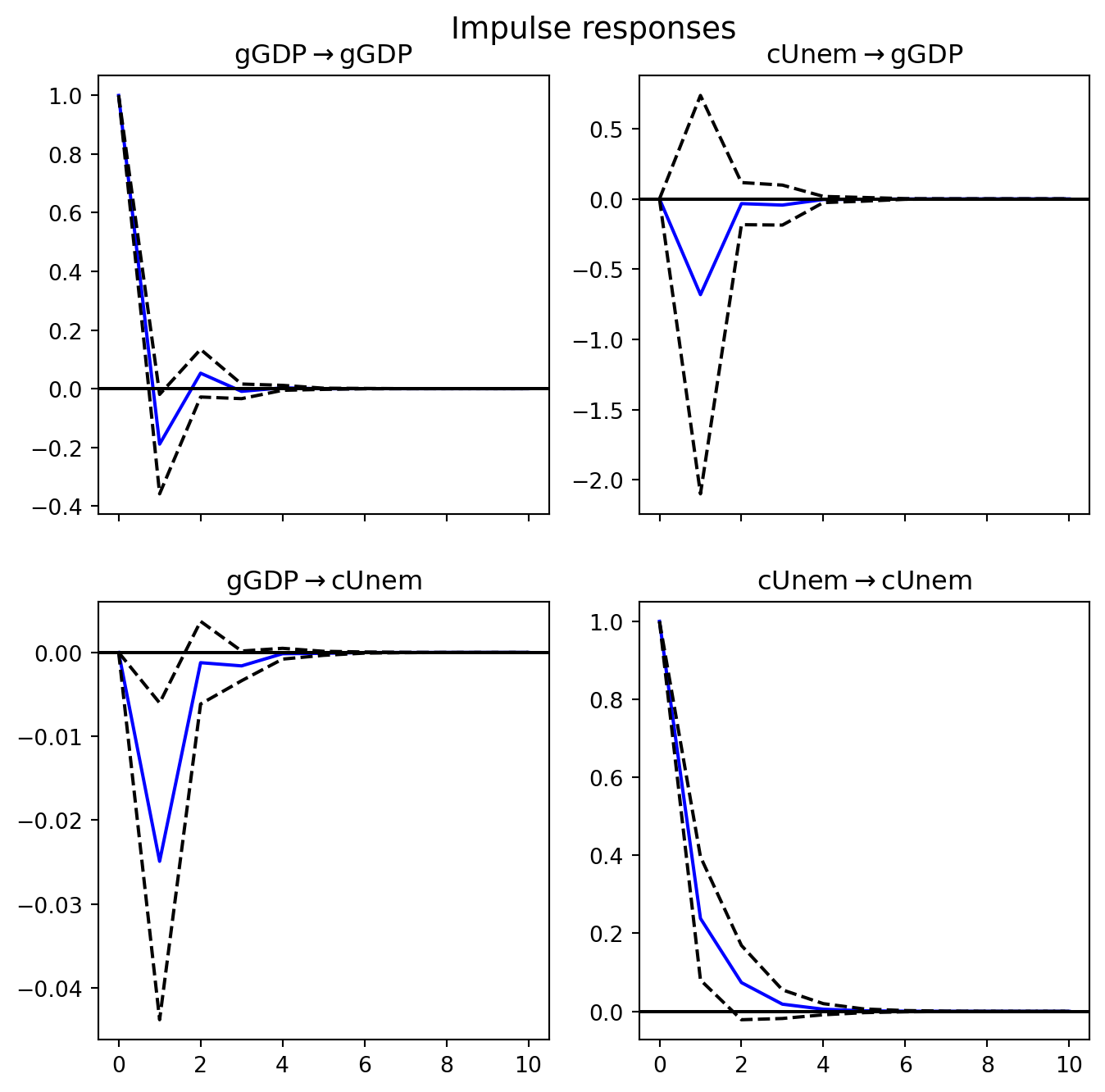
An Impulse Response Function (IRF) traces the effect of a one time shock to one variable on the entire system over time. It allows us to understand how a shock today affects each variable in the system, the direction and magnitude of the response, and how persistent the effect is.
A key complication arises because the residuals, by construction, are correlated, \(Cov(\epsilon_t) = \Sigma \ne I\). As a result, a shock to one equation is not isolated, making interpretation difficult. To address this, we transform the residuals as: \[\epsilon_t = P u_t\] where \(u_t\) is the vector of orthogonal shocks (uncorrelated) and \(P\) is a matrix such that \(PP'=\Sigma\).
This transformation allows us to interpret shocks as independent innovations. Substituting into the Moving Average Representation of the VAR system:
where: \(\Psi_h=\Phi_hP\). Each \(\Psi_h\) describes the response of the system at horizon \(h\) to a one-unit orthogonal shock to one variable, holding shocks to all other variables equal to zero.
Each column of \(\Psi_h\) corresponds to a specific shock, specifically, column \(i\) is the response to a shock in variable \(i\). The rows represent the responses of all variables in the system.
The impulse response functions for our model are obtained as follows:
Each figure in the panel shows how one variable responds over time to a one-time shock in another variable. The horizon tells us how long the effect lasts.
Suppose Mexico experiences a sudden surge in manufacturing exports due to nearshoring demand from the U.S., stronger than anticipated, how does unemployment respond over the next quarters?
NotePractice
Apply Vector Autoregression (VAR) techniques to analyze the dynamic interaction between long-term interest rates and market uncertainty. Using data on the 10-year U.S. Treasury yield and the VIX index, this exercise explores how changes in financial conditions and perceived risk evolve jointly over time. Understanding the relationship between interest rates and volatility is essential in finance, as shifts in risk sentiment and term structure dynamics influence asset pricing, portfolio allocation, and hedging strategies.
We will estimate a VAR model, select the appropriate lag length, and evaluate its adequacy through diagnostic and stability tests. Finally, impulse response functions will be used to examine how unexpected changes in long-term yields affect market volatility, and vice versa. The goal of the exercise is to move beyond model estimation and develop the ability to interpret dynamic relationships in financial markets in a rigorous and economically meaningful way.
6.2 Cointegration
If we regress one nonstationary series on another, we may obtain apparently strong results even when the variables are unrelated. This is the problem of spurious regression. This is why we have emphasized the importance of testing for unit roots and, when needed, transforming the data by taking differences before modeling.
This, however, might create an important issue, if two nonstationary variables are linked by an economic equilibrium relationship in the long run, and we difference them mechanically, we may remove the long-run information contained in the levels of the variables, which eliminates precisely the information we care about most.
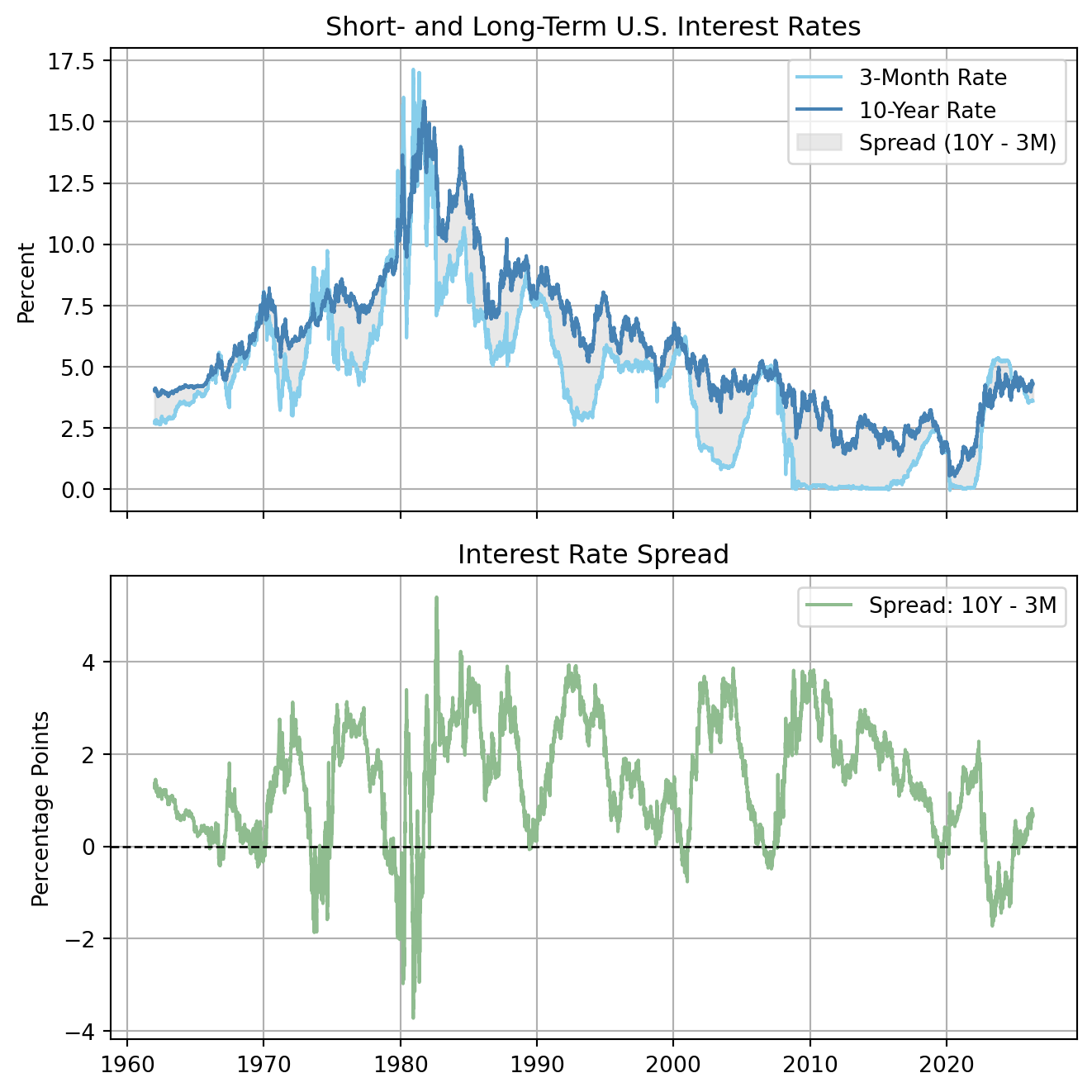
Take, for instance, income and consumption. Theory suggests both series grow over time, but may not be stationary on its own. Similarly, the prices of closely related financial assets, such as the interest rate on short vs long term bonds (Figure 6.1 top). Even though both series move over time, they do not drift apart indefinitely. Instead, they remain tied to one another by an equilibrium condition, so the spread (\(r_{10y} - r_{3m}\)) is relatively stable (Figure 6.1 bottom). That’s because they have a common stochastic trend.
Figure 6.1: US Treasury Maturity, 3-month vs 10-year
If we difference these variables blindly, they may lose meaningful long-run structure. Instead, we want a framework that tells us whether a long-run relationship exists. Cointegration is designed to address such cases, allowing us to work with variables that are individually nonstationary, while still capturing the possibility that they move together over time in a stable long-run relationship.